
In questo tutorial andremo a vedere come eseguire il caricamento dei dati da cartella mediante Power Query.
Questa funzione può risultare estremamente utile poiché con pochi semplici click andremo a svolgere le seguenti azioni:
1) Leggere i file (xlsx, csv, txt, ...) presenti in una cartella
2) Prenderemo uno di questi file da utilizzare come esempio per eseguire delle azioni di pulizia
3) Le azioni svolte al punto (2) verranno automaticamente eseguite su tutti i file presenti nella cartella
4) I file verranno automaticamente accodati in un'unica tabella pronta per essere caricata nel nostro modello dati
Il requisito fondamentale per poter utilizzare questo strumento è che tutti i file presenti nella cartella siano strutturati allo stesso modo o quantomeno siano essi riconducibili ad un'unica struttura che ne consenta l'accodamento.
In sintesi, più i file risultano omogenei tra loro e più semplice saranno le operazioni da eseguire.
I file che caricheremo all'interno della cartella sono dei semplici file .csv, strutturati nel modo che segue:
Variable;Description;Value;Units;
PzScarti;;0;;
PzDone;;54;;
DataOra_InizioProd;;28/09/23 10:35:56;;
BatchName;;;;
DataOra_FineProd;;23/09/28 10:51:53;;
Hanno dunque la particolarità di svilupparsi in senso verticale, e di utilizzare come separatori il ";"
Ciascuno di questi file presenta nel nome la data e l'orario di elaborazione (es°20230928_105154_Produzione.csv). Essendo queste due info relativamente importanti è necessario riuscire ad estrapolarle.
L'output risultante dovrà essere qualcosa di simile (una riga per ciascun file csv):

In calce al tutorial lascio qualche file di esempio così che possiate seguire gli step che seguiranno.
Step1 - Avvio procedura caricamento da cartella
La prima cosa da fare dopo aver preparato i file csv nella cartella è aprire un file excel, accedere al tab "Data" (io utilizzo la versione inglese, quindi aiutatevi con le immagini e il traduttore se vi serve), menu a tendina "Get Data" , voce "Da File" ed infine "Da Cartella":
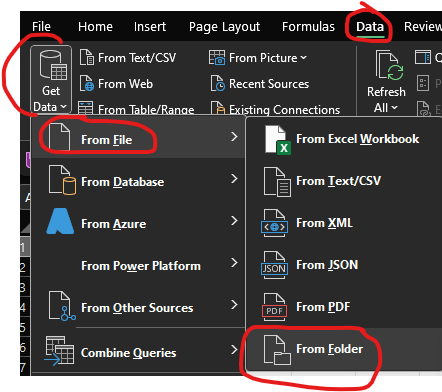
Si aprirà una finestra dal quale scegliere il percorso del proprio pc che porta alla cartella contenente i file da analizzare.
Una volta dato l'invio vi troverete una schermata simile:
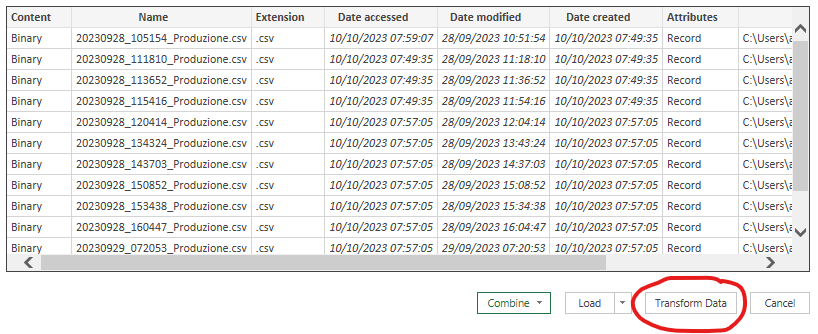
Cliccate su "Transform Data", avvierete l'editor di Power Query.
Step2 - Prima Fase di Pulizia Dati
Abbiamo eseguito questi step poiché siamo interessati non solo ad estrarre i singoli valori da ciascun file .csv, ma anche le info legate al file stesso (come il nome). In questo modo sarete giunti ad una tabella dalla quale è possibile ottenere le informazioni utili:
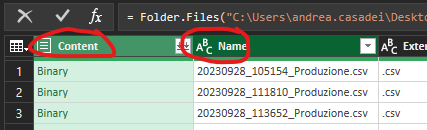
Le prime due colonne ci servono perché una contiene il contenuto dei singoli file, l'altra contiene il nome di ciascuno di essi. Quindi le selezioniamo e con il tasto destro clicchiamo sulla voce "Remove Other Columns":
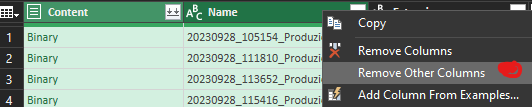
Ora che vi sono rimaste solo le due colonne a voi utili basta cliccare sul piccolo simbolo con le due frecce che puntano verso il basso nell'intestazione della prima colonna "Content" (quella che contiene i binary).
Power Query mostrerà una schermata dalla quale si potrà leggere il contenuto di uno dei csv, così come lui andrebbe a rappresentarlo. In questa schermata è sufficiente controllare se il sistema ha scelto il delimitatore corretto e se le colonne individuate sono poi quelle che ci interessano (non preoccupatevi se ne mostra alcune che non servono, le puliremo in uno step successivo):
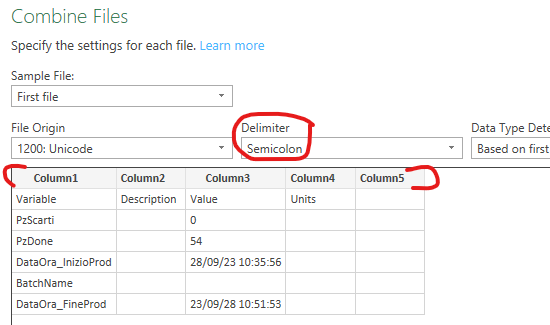
Diamo conferma cliccando su Ok.
Ora vedrete che Power Query ha creato in automatico tutta una serie di step che eseguono le fasi che ho descritto all'inizio del tutorial:
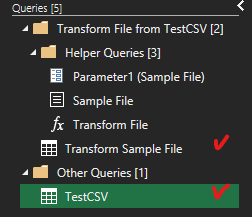
Ho evidenziato quelle due tabelle perché la prima in alto è la tabella di esempio che dobbiamo utilizzare per applicare tutte le trasformazioni che vogliamo ai singoli file prima che questi vengano accodati in una tabella unica (la seconda tabella evidenziata in basso).
Al momento le fasi di pulizia non sono corrette, pertanto dobbiamo:
1) Nell'ultima tabella in basso, tra gli step della query, andare a rimuovere il passaggio "Changed Type" (l'ultimo della lista) così da evitare un messaggio di errore (per intenderci la query è quella che nell'immagine compare con il nome TestCSV). Se cliccate su questa query vedrete poi i passaggi di cui è composta sul lato destro dell'interfaccia.
2) Cliccare sulla prima tabella evidenziata (nell'immagine si chiama "Transform Sample File") ed eseguire i passaggi di pulizia richiesti (vedi Step3).
Step3 - Pulizia Tabella di Esempio
In questa tabella (Transform Sample File) vi è un solo passaggio chiamato "Source", tramite l'editor avanzato al quale potete accedere selezionando il tab "View" --> "Advanced Editor" andate a copiare il seguente codice (state attenti che probabilmente, se usate una lingua diversa dall'inglese alcuni nomi dei parametri potrebbero cambiare, ad esempio "Parameter1" come primo argomento della funzione Csv.Document):
Codice: Seleziona tutto
let
Source = Csv.Document(Parameter1,[Delimiter=";", Columns=5, Encoding=1200, QuoteStyle=QuoteStyle.None]),
#"Removed Other Columns" = Table.SelectColumns(Source,{"Column1", "Column3"}),
#"Transposed Table" = Table.Transpose(#"Removed Other Columns"),
#"Promoted Headers" = Table.PromoteHeaders(#"Transposed Table", [PromoteAllScalars=true]),
#"Changed Type" = Table.TransformColumnTypes(#"Promoted Headers",{{"Variable", type text}, {"PzScarti", Int64.Type}, {"PzDone", Int64.Type}, {"DataOra_InizioProd", type datetime}, {"BatchName", type text}, {"DataOra_FineProd", type datetime}}),
#"Reordered Columns" = Table.ReorderColumns(#"Changed Type",{"Variable", "DataOra_InizioProd", "DataOra_FineProd", "PzDone", "PzScarti", "BatchName"}),
#"Removed Other Columns1" = Table.SelectColumns(#"Reordered Columns",{"DataOra_InizioProd", "DataOra_FineProd", "PzDone", "PzScarti", "BatchName"})
in
#"Removed Other Columns1"1) Aggiungere una "," al termine del passaggio Source (o Origine)
2) Incollare tutto il codice che segue fino in fondo
3) Nel passaggio chiamato #"Removed Other Columns" vedete che la funzione Table.SelectColumns() ha come argomento il richiamo al primo passaggio, dovrete sostituirlo con il nome del vostro primo passaggio (es° Origine).
4) Questo passaggio --> #"Removed Other Columns" = Table.SelectColumns(Source,{"Column1", "Column3"}), fa riferimento ai nomi delle colonne presenti nel mio file (versione inglese), quindi dovrete sostituire "Column1" e "Column3" con i rispettivi valori (se usate la versione in italiano).
Avrete i dati disposti nel verso corretto e per le sole colonne che vi interessano.
Le operazioni eseguite sono state tutte svolte tramite l'interfaccia di Power Query, senza la necessità di scrivere codice M manualmente.
Ovviamente questo era un codice creato ad hoc per risolvere questo specifico problema, di norma quello che dovrete fare è agire sulla query che contiene la trasformazione del file di esempio (Transform Sample File) ed eseguire qui tutte le azioni di pulizia del dato. Tutte le azioni che andrete ad intraprendere verranno tradotte in linguaggio M ed inoltre verrà creata una funzione custom che sarà applicata a ciascun file caricato all'interno della cartella, tutto questo in modo del tutto automatico senza che l'utente debba preoccuparsi di scrivere del codice.
Se avrete fatto tutto nel modo corretto, ora cliccando sull'ultima tabella evidenziata in rosso nello step precedente vedrete che il file finale sta prendendo forma, l'unica cosa che manca è il nome di ciascun file.
In questa tabella risultante vedrete che di step ne sono stati scritti diversi in automatico da PQ, se cliccate sul terzo a partire dal basso "Invoke Custom Function1" vedrete che prima di andare ad eseguire questa operazione il nome di ciascun file era presente nella tabella, ma con il secondo passaggio a partire dal basso la procedura ha selezionato solo una colonna da tenere e quindi l'info con il nome del file si è persa.
Basta dunque agire su questo passaggio:
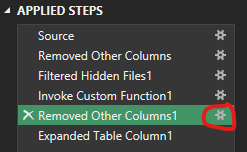
Cliccando sul simbolo a forma di ingranaggio e nella schermata che apparirà mettere la spunta anche sulla colonna "Name":
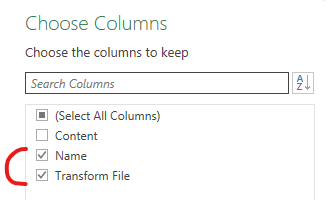
A questo punto diamo conferma e torniamo all'ultimo step di questa query. Cambiamo il formato dati di ciascun campo così da avere quelli corretti ed il gioco è fatto. Siamo pronti per caricare il risultato di questa query in una tabella su un foglio excel, oppure come sola connessione per un modello dati.
Ora non resta che aggiungere altri file all'interno della cartella di lavoro originaria ed aggiornare la query così da poter avere in pochi istanti i nostri file elaborati ed aggregati nel modo corretto.
Il tutto è stato eseguito senza ricorrere a codice M, ma utilizzando solo i comandi dell'interfaccia grafica.
Andrea