
Tabella dei fatti "classica"
Come abbiamo già anticipato nei precedenti tutorial, in uno star schema "perfetto" le tabelle dei fatti hanno le seguenti caratteristiche:
- una riga per ciascun evento "elementare" (es. ciascun prodotto di una singola vendita)
- una colonna per ciascun attributo, le quali idealmente sono tutte chiavi esterne verso le tabelle dimensionali (es. data, id_cliente, id_prodotto...)
- una colonna per ogni metrica su cui compiere dei calcoli (es. quantità, prezzo di vendita, costo...)
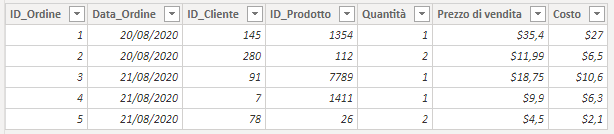
Esempio di fact table "classica"
Tabella dei fatti unpivotizzata
Esiste però un'altra possibile struttura per le tabelle dei fatti, che in taluni casi viene scelta per i vantaggi immediati che offre: la tabella dei fatti unpivotizzata. Di che si tratta? Le colonne degli attributi hanno le stesse caratteristiche di cui sopra, ma la colonna delle metriche (non importa quante siano) diventa una sola. In pratica, si prendono le colonne delle metriche (che nella struttura classica sono distinte) e si opera un unpivoting, trasformando queste N colonne in 2 sole colonne finali: una con la descrizione della metrica, e una con le quantità da aggregare.
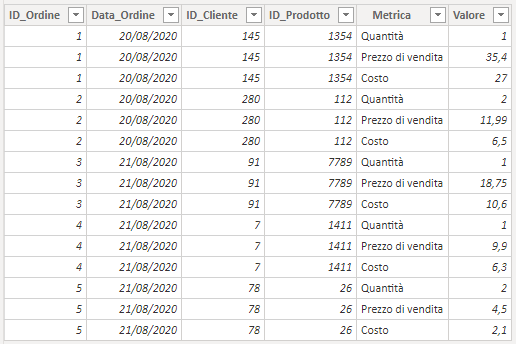
Esempio di fact table "unpivotizzata"
Pertanto, in quest'ultima colonna - per seguire l'esempio iniziale - avremo un "mix" di quantità, prezzi di vendita e costi. Da quest'ultima affermazione si intuisce già qual è uno dei punti deboli di questa struttura: non sempre è possibile definire un tipo di dato ottimale per tutte le metriche che la colonna andrà ad ospitare.
Ma andiamo con ordine e vediamo prima quali sono i vantaggi di questa struttura alternativa:
- E' semplicissimo definire uno slicer per decidere quale misura mostrare nel report, rendendoli interattivi (le metriche sono organizzate in riga, quindi è sufficiente impostare lo slicer sulla colonna delle descrizioni delle metriche)
- Per la stessa ragione, è altrettanto semplice definire dei ruoli con permessi di visualizzazione solo su alcune metriche e non su altre
- Se occorre aggiungere metriche nuove al dataset, è molto più semplice accodarle a quelle già esistenti, anziché aggiungere ulteriori colonne
I problemi che possono derivare dalla struttura unpivotizzata riguardano invece:
- La già anticipata difficoltà nel definire un tipo di dato che si adatti a tutte le metriche della tabella
- Le prestazioni e le dimensioni del modello: spesso gli stessi calcoli richiedono un maggior tempo di esecuzione rispetto alla struttura classica, e le tabelle diventano più grandi: c'è infatti una maggior replicazione di dati, nelle colonne degli attributi, anche se la loro cardinalità (ovvero il numero di elementi distinti), non aumenta, e una maggior difficoltà del motore di compressione nel trovare un setup ottimale.
- Alcuni calcoli potrebbero essere sensibilmente più complessi, e lenti, lavorando su una sola colonna anziché su N colonne diverse; si perde inoltre la possibilità di sfruttare la context transition nelle formule DAX, a meno di creare un ulteriore indice univoco per ciascun record della tabella unpivotizzata.
Conclusioni
Qual è dunque la struttura migliore per una fact table? Dipende. Come regola generale, la struttura "classica" è quella che garantisce la maggior flessibilità di utilizzo e mette più al riparo da spiacevoli sorprese alle quali poi, una volta riscontrate, potrebbe non essere più così facile porre rimedio. MA: se le vostre metriche sono omogenee per unità di misura e quindi tipo di dati, e siete ragionevolmente certi di non doverne più aggiungere di diversa natura; se non avete tabelle di dimensioni enormi, che possono subire un consistente degrado di prestazioni con la struttura unpivotizzata; se il vostro report può giovarsi della possibilità di mostrare metriche alternative in una stessa visualizzazione, e/o della definizione di ruoli che mostrino/nascondano un determinato set di metriche a seconda dell'utente collegato... allora, la fact unpivotizzata può essere una valida alternativa.
Nel prossimo tutorial parleremo delle tabelle dimensionali, e di cosa possiamo fare se non le abbiamo a disposizione nella sorgente dati. Grazie per l'attenzione e a presto!