
_______________________________________________
Star Schema (schema a stella)
Come accennato in precedenza, questo è il tipo di modello principale usato nella Business Intelligence. La combinazione tra facilità di lettura, prestazioni e versatilità lo rendono il "faro" verso cui dovremmo sempre cercare di dirigere i nostri dati, per trarne report potenti ed efficaci.
Il nome (schema a stella) deriva dalla rappresentazione grafica che si può dare al modello nella sua forma più semplice: al centro una tabella dei fatti (vedi pt. 1), e intorno ad essa una o più tabelle dimensionali, tutte in relazione uno-a-molti con la tabella dei fatti.
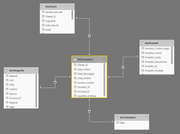
Rappresentazione di uno star schema
Chi (come me ad esempio) proviene da una lunga esperienza in Excel, è abituato a ragionare in termini di tabelle "monolitiche", che contengono al loro interno tutte le informazioni che occorrono all'analisi. Spesso queste tabelle vengono generate a partire da sorgenti eterogenee (altri file di excel, testo, esportazioni da database, etc), e consolidate a colpi di CERCA.VERT (o CERCA.X, se siete così aggiornati!
Questo concetto, lavorando in PowerBI o in Power Pivot, va completamente ribaltato: per facilitare il lavoro di analisi e ottimizzare lo spazio occupato dal modello, le tabelle vanno mantenute distinte utilizzando opportuni criteri di modellazione, e anzi, se ci viene consegnata una tabella monolitica, sarà opportuno "frazionarla" utilizzando Power Query, in modo da riprodurre uno schema a stella.
_______________________________________________
Snowflake Schema (schema a fiocco di neve)
Lo schema a fiocco di neve (Snowflake schema) è una variante dello schema a stella. Si differenzia da esso in quanto le tabelle dimensionali non necessariamente sono in relazione diretta con la tabella dei fatti, ma possono anche essere in relazione tra di loro, formando una sorta di "catena" gerarchica.
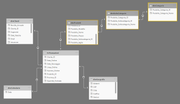
Rappresentazione di uno snowflake schema
In uno schema a fiocco di neve, la ridondanza dei dati è ridotta al minimo o del tutto azzerata: ogni tabella ha solo l'insieme minimo di informazioni che occorrono, e "preleva" le altre dalla catena di relazioni impostata. Quindi la tabella dimensionale "dimProdotti", non avrà una colonna "Categoria" e una "Sottocategoria", contenenti dei testi che si ripetono per ogni prodotto che vi appartiene. Avranno invece solo una colonna "Prodotto_Sottocategoria_ID" che si collegherà a un'altra tabella dimensionale "dimSottoCategorie". Questa a sua volta avrà una colonna "Prodotto_Categoria_ID" che si collegherà a un'ulteriore tabella "dimCategorie", che chiude la catena di relazioni e ha una sola riga per ogni categoria.
Questo tipo di modello, descritto in questo modo, sembra ottimale, e da un certo punto di vista lo è. Perché allora si consiglia di tendere sempre verso lo star schema, anziché lo snowflake? Si tratta di contemperare varie esigenze: un modello a fiocco di neve è il migliore per ridurre al minimo le dimensioni del modello e garantire l'integrità dei dati (una categoria cambia nome? Basta aggiornare la sua riga nella tabella "Categorie", senza dover modificare ogni elemento della tabella Prodotti che rientra in quella categoria). Tuttavia, è un modello più difficile da navigare e più scomodo per l'utente, che deve cercare i campi per l'analisi in molte più tabelle. Inoltre, se il modello è molto corposo e di conseguenza anche le "ramificazioni" di dimensioni lo diventano, ci può essere anche un certo decadimento prestazionale.
Per questa ragione, quando ci si trova ad avere un modello perfettamente normalizzato, si tende a ricondurlo, in tutto o in parte, a un modello a stella, denormalizzando alcune tabelle. Il concetto di normalizzazione e denormalizzazione va un po' oltre questa trattazione introduttiva, comunque si tratta in sostanza delle tecniche qui sopra enunciate, ovvero frazionare ciascuna tabella riducendola ai minimi termini (normalizzazione) o al contrario fare tabelle più corpose che contengono anche informazioni ripetute (denormalizzazione). Spesso non si tratta di "bianco o nero", bensì di trovare un giusto equilibrio tra le varie esigenze di cui abbiamo parlato, per avere un modello ottimale dal punto di vista delle prestazioni, della facilità di utilizzo e della flessibilità
Conclusioni
Abbiamo dunque presentato i tipi di modello con cui più spesso avremo a che fare, e a cui dovremo cercare di ricondurre sempre i nostri dati, per garantire prestazioni ottimali e ottenere la massima potenza di analisi con la minor complicazione possibile nel codice che andremo a scrivere per calcolare le nostre metriche.
Per ulteriori approfondimenti, consiglio la visione di questo video di Lodovico D'Incau, e la lettura di questo libro di Alberto Ferrari e Marco Russo: davvero una lettura fondamentale per chi si approccia in modo "serio" all'utilizzo di Power BI
Nel prossimo tutorial approfondiremo ulteriormente questi concetti, entrando più nel dettaglio sulla struttura delle tabelle dei fatti. A presto!